
Web Scraping Performance Tuning With fastnext()
Scraping websites can be a time consuming process and when limited computing resources are available, combined with the need for frequent and up to date data, having a fast running robot is essential. A single robot can take anywhere from hours to weeks to complete a run, thus making a robot just fractionally more efficient could save a lot of valuable time.
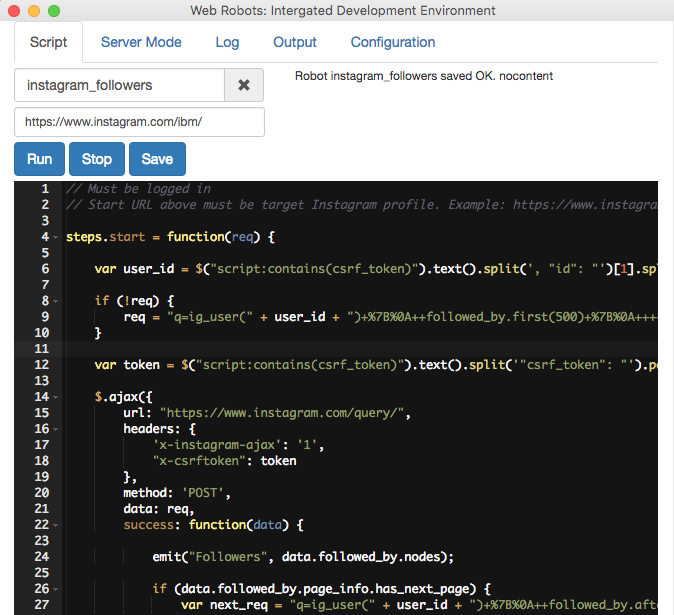
There are a number of ways to optimize your robot to run faster, replacing setTimeout with our internal wait function, careful usage of loops, not using excessive delay timers in step done function, etc. However, one of the best methods so far been has proven to be using ajax requests instead of visiting a website […]

![Screen Shot 2016-03-01 at 3.22.41 [...]
</p srcset=](https://webrobots.io/wp-content/uploads/2016/03/Screen-Shot-2016-03-01-at-3.22.41-PM-1024x849.png)