New Dataset – UK LPA Search
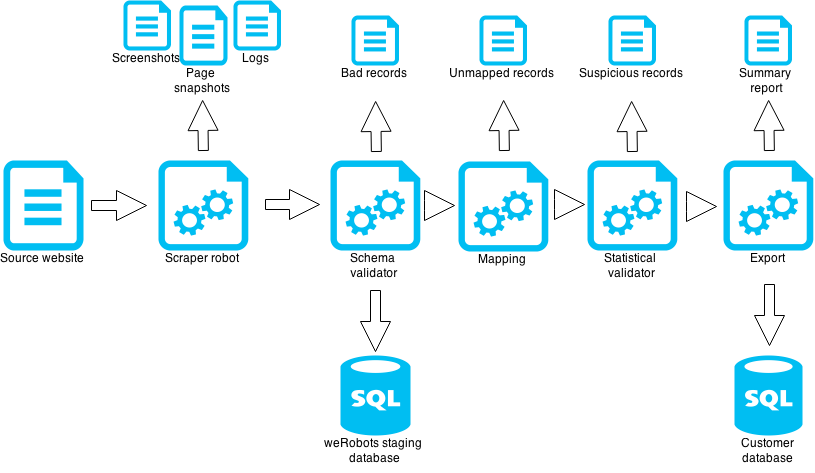
We are excited to announce UK LPA Search – it is a search engine for all UK’s local planning authorities. Until now there was no possibility to search LPA databases from one place. One had to find each LPA’s website and search inside it. Considering there are few hundred of them – this would not be an easy task for a human. Our robots have no problems indexing all databases and providing them as a single dataset.
A bonus point – we geocoded all requests and display them on a map. Therefore anyone can see what building permits are being issues around them. Example: Map of building permits in London […]
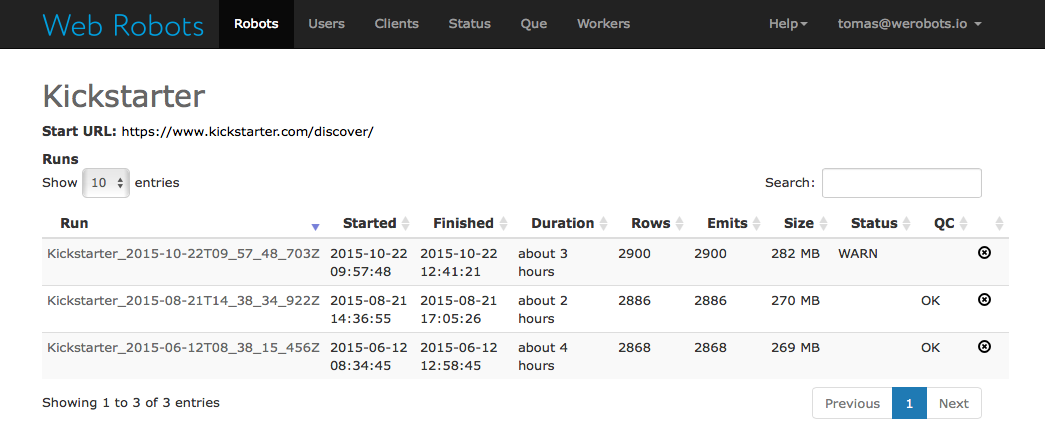
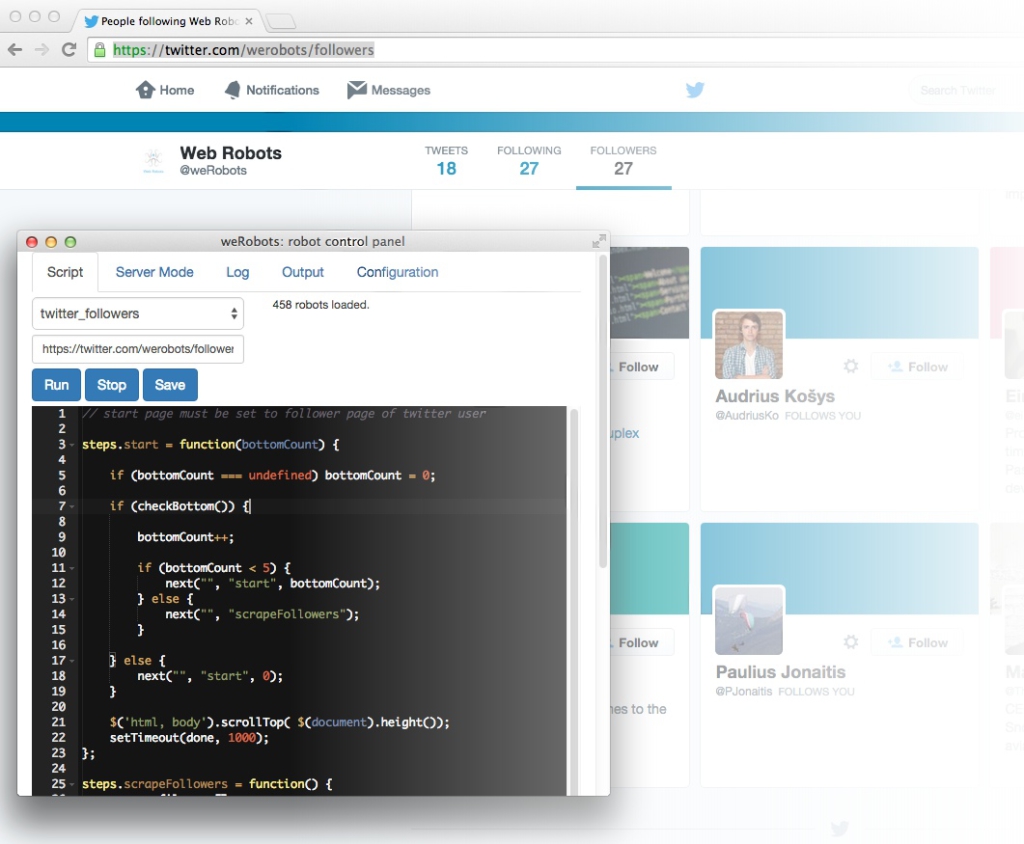 Easy Twitter Scraping
Easy Twitter Scraping