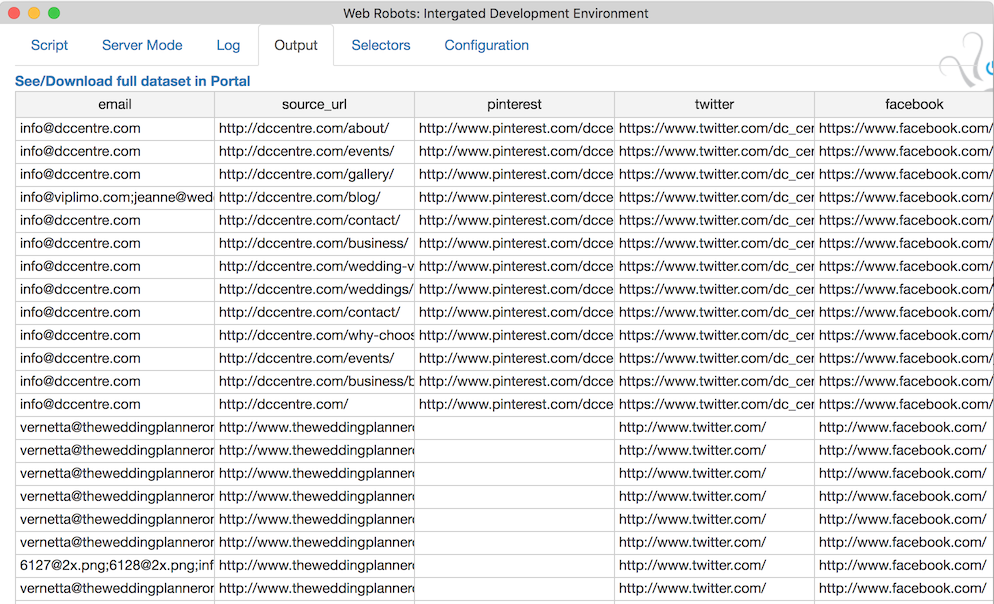
Analysis of different web scraping approaches, best practices and challenges. Overview of Web Robots scraper features.
15
Feb, 2023
New Functions Added
Web Robots scraping framework documentation has been updated with new functions:
- blockImages() – changes browser settings regarding image downloading. This function is useful in scenarios when bandwidth is a concern. Sometimes it results in faster crawling speeds.
- allowImages() – reverses browser settings changes made by blockImages().
- closeSocket() – closes all idle socket connections in browser.
Web Robots have been using these functions on the internal platform for over 6 months and they proved to be great help in some scenarios. Now they are available in our public extension.