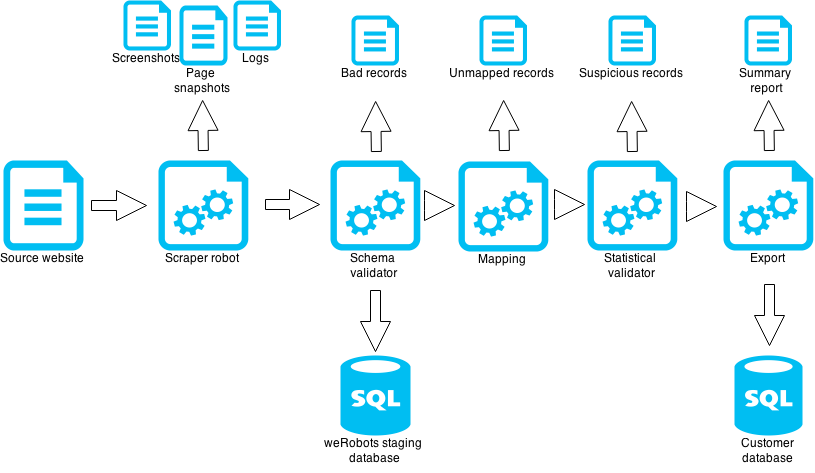
Analysis of different web scraping approaches, best practices and challenges. Overview of Web Robots scraper features.
24
Feb, 2017
Scraping Extension Update – version 2017.2.23
Recently we rolled out an updated version of our main web scraping extension which contains several important updates and new features. This update allows our users to develop and debug robots even faster than before. So what exactly is new?
- jQuery has been upgraded from version 1.10.2 to 2.2.4
- done() now can take a milliseconds delay parameter. For example done(1000); will delay step finish by 1 second.
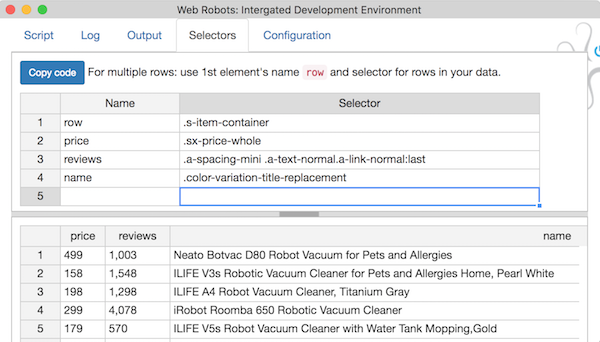
- New tab Selectors which allows testing selectors inline and generates robot code. Selectors are immediately tested on browser’s active tab so developer can see if they work correctly. Copy code button copies Javascript code to clipboard which can be pasted directly into robot’s step.
[…]

![Screen Shot 2016-03-01 at 3.22.41 [...]
</p srcset=](https://webrobots.io/wp-content/uploads/2016/03/Screen-Shot-2016-03-01-at-3.22.41-PM-1024x849.png)
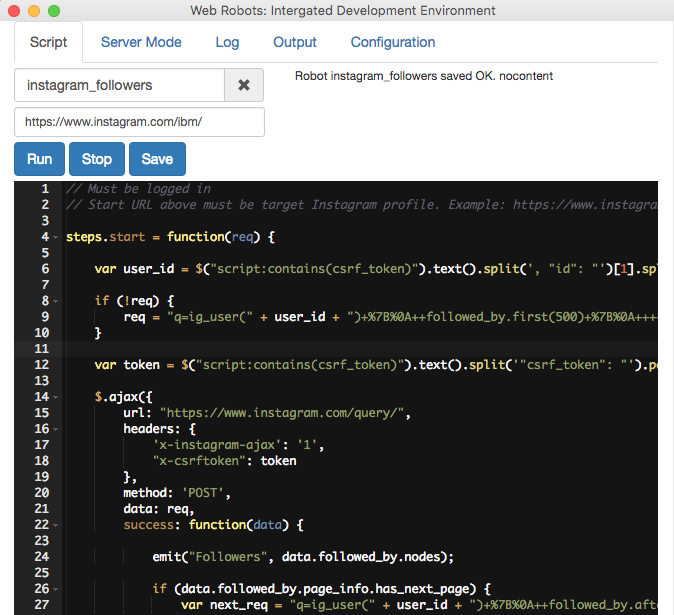
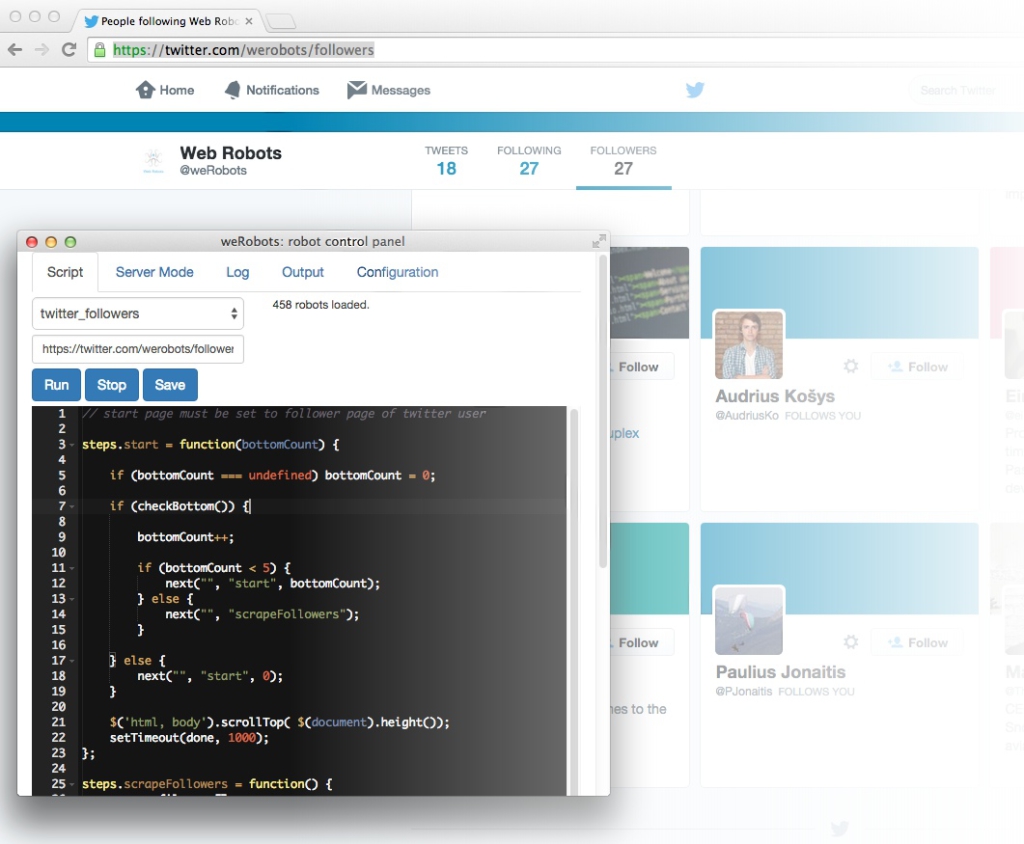 Easy Twitter Scraping
Easy Twitter Scraping