At Web Robots we often get inquiries on projects to crawl social media links and emails from specific list of small websites. Such data is sought after by growth hackers and sales people for lead generation purposes. In this blog post we show an example robot which does exactly that and anyone can run such web scraping project using Web Robots Chrome extension on their own computer.
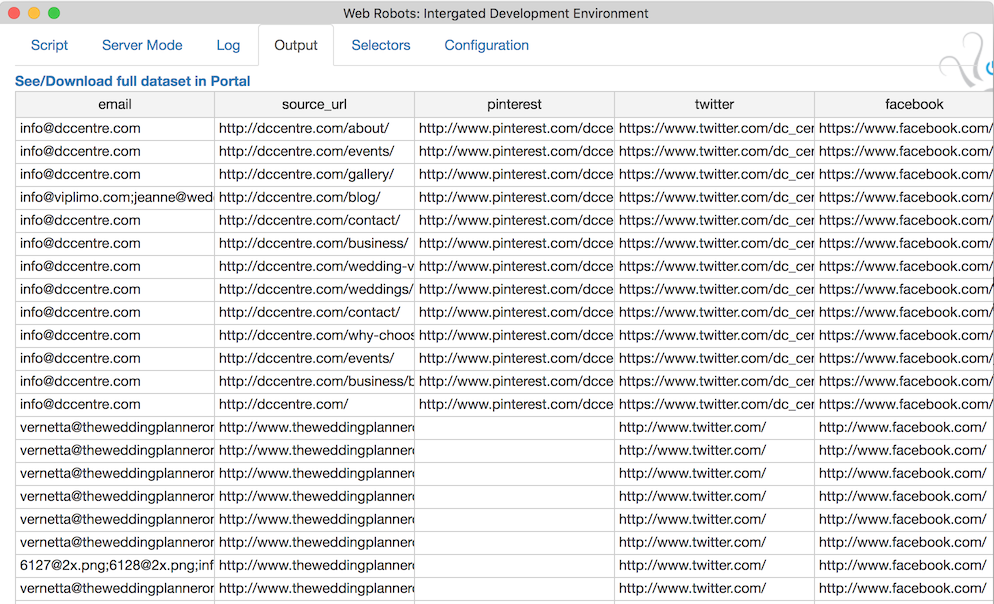

To start you will need account on Web Robots portal, Chrome extension and thats it. We placed a robot called leads_crawler in our portal’s Demo space so anyone can use it. In case robot’s code is changed below is complete source code for this robot. You must edit variable on lines 14-18 to contain the list of target websites to crawl and run the robot. Then previous data on the Output tab and download it from portal once robot is finished. You will get a nice CSV file with data which can be used in your further leads processing workstream.
Robot’s source code:
var DEPTH = 2;
var EMAIL_PATTERN = /([a-zA-Z0-9._-]+@[a-zA-Z0-9._-]+\.[a-zA-Z0-9._-]+)/gi;
var SOCIAL_MEDIA = [
'facebook.com',
'linkedin.com',
'instagram.com',
'youtube.com',
'twitter.com',
'pinterest.com',
'plus.google.com',
'blogspot.com'
];
var websites = [
"http://dccentre.com/",
"http://www.theweddingplanneromaha.com/",
"http://www.effortlesseventsidaho.com/"
];
steps.start = function() {
setSettings({skipVisited:true});
setRetries(5000, 2, 1000); // 5 sec retry timer to skip bad pages quickly
websites.forEach(function(v, i) {
next(v, "crawl", 0);
});
done();
};
steps.crawl = function(depth){
depth++;
var emails = _.uniq(returnEmails());
var social = returnSocial();
var urls = returnURLs();
dbg(urls);
if(emails.length || social.length) {
var data = {
'email' : emails.join(';'),
};
$.extend(data, social);
emit('Leads', [data]);
}
if(depth < DEPTH) {
urls.forEach(function(v) {
next(v, 'crawl', depth);
});
}
done();
};
returnURLs = function() {
var urls = [];
$('a:visible').each(function (i,v) {
var url = $(v).prop('href').split('#').shift();
if(isValidLink(url)) {
urls.push(url);
};
});
return(_.uniq(urls));
};
returnSocial = function() {
var urls = [];
var social = {};
$('a:visible').each(function (i,v) {
urls.push($(v).prop('href'));
});
_.uniq(urls).forEach(function(link) {
var domain = link.split('://').pop().split('www.').pop().split('/').shift().toLowerCase();
var pos = _.indexOf( SOCIAL_MEDIA, domain);
if(pos !== -1) {
social[SOCIAL_MEDIA[pos].split('.').shift()] = link;
};
});
return(social);
};
returnEmails = function() {
return $('*').html().match(EMAIL_PATTERN);
};
isValidLink = function(link){
// here we check for all bad stuff in links
if(_.indexOf(SOCIAL_MEDIA, link.split('://').pop().split('www.').pop().split('/').shift()) !== -1) {
return false;
}
if ((link === undefined) || (typeof link !== "string") || (link.length < 12)) {
return false;
}
if (
// positives - must be present
!(link.includes(document.domain)) ||
!link.startsWith("http") ||
// negatives - must not be present
link.includes(".zip") ||
link.includes(".csv") ||
link.includes(".mpg") ||
link.includes(".mpeg") ||
link.includes(".gz") ||
link.includes(".jpg") ||
link.includes(".jpeg") ||
link.includes(".png") ||
link.includes(".pdf") ||
link.includes(".doc") ||
link.includes(".xls") ||
link.includes(".ppt") ||
link.includes(".avi") ||
link.includes(".tif") ||
link.includes(".exe") ||
link.includes(".psd") ||
link.includes(".eps") ||
link.includes(".txt") ||
link.includes(".rtf") ||
link.includes(".wmv") ||
link.includes(".odt") ||
link.includes(".css") ||
link.includes(".js") ||
link.includes("mailto:") ||
link.includes("facebook") ||
link.includes("google") ||
link.includes("twitter") ||
link.includes("youtube") ||
link.includes("linkedin") ||
link.includes("download") ||
link.includes("pinterest")
) {
return false;
} else {
return true;
}
};