Data is only valuable if it can be trusted. At weRobots we spend as much effort on validating data as on collecting it. It is a multi stage process.
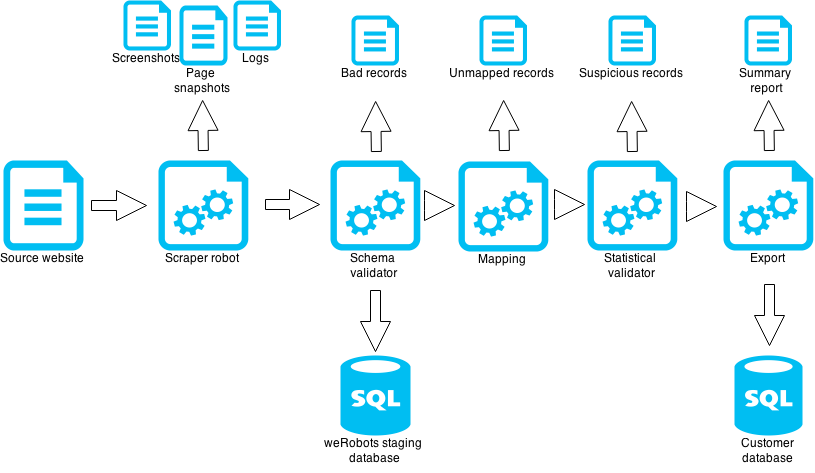
- Scraping
Initial checks happen in scraper robots. Robot crawls target website and looks for data. Captured data is sent to our staging database. Many abnormal situations can arise at this stage:
- Site may be down. Robot will log warnings and will retry pages that do not respond. Usually outage is temporary and robot resumes without intervention
- Site layout changes. If robot cannot find navigation links or data it will stop and report error so that our team can review the situation and the appropriate action.
For diagnostics and traceability robot logs all actions it performs and it can take screenshots and content snapshots of source website. This can be important if we need to know what exactly was displayed on a source website at the time of scrape.
- Schema Validation
Scraped data is validated to match predefined schema. For example data about product scraped from an e-shop may have to pass the following validations:
- Product ID that is numeric
- Price is a decimal number with two decimal places. Price must be greater than 0.
- Product has description that is at most 200 characters long
- Optional field “Availability date” is a date
Records that faill to pass schema validation are stored in “Bad records” table with an explanation on why validation failed.
- Mapping
Mapping step maps source identifiers to customer identifiers. For example e-shop product ID might be matched to customer internal product ID. Unmapped records are reported. In some workflows we automatically create new records in customer’s system (for example when we find new products in source website we create new product IDs in customer’s database). This step is a great advantage when scraped data is integrated with data that customer already has.
- Statistical validation
Statistical validation step checks if new scraped data is similar to previous good scrapes. Within allowable tolerances we check that:
- Robot collected similar amount of records
- Numeric fields have similar averages
- Text fields have similar lengths
- Robot run took similar amount of time
- Additional custom calculation checks based on dataset
We flag suspicious records and suspicious scraping runs for our staff or customer to review.
- Export
Export step moves data to customer DB. We support export to all relational databases, dumps to CSV, JSON and XML. Export can be batch or real-time replication.
Reports Final summary report is produced after all steps finished and allows us and customer review all information in one place.