
Free Data and Projects
Projects We Worked On
- Mass Transit (case study). Scraping several mass transit sites for various countries to collect bus and train schedules as datasets. In this project we had to build scraping robots that could crawl through several pages and dynamically generate a list of links to spider through, fill out and submit forms. Another challenge in this project was to extract usable dataset from messy HTML auto-generated from Microsoft Word documents.
- Kickstarter. We took a challenge to scrape the entire Kickstarter website to gather data about all ongoing and completed projects. Kickstarter is a website utilising modern technologies like infinite scroll and AJAX data loading. Our scraping technology worked spectacularly well on this source. Later we decided to release these datasets to public.
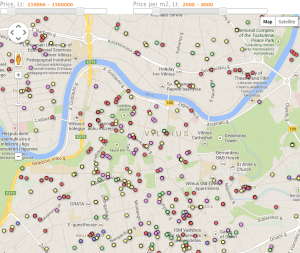
- Real Estate Map. We scraped a real estate portal to build a dataset of all listings. Listings were geocoded and presented on Google Maps using Fusion Tables. Ability to filter listing markers on the map by price and price per square meter.
Voting Records. We had several projects to crawl and deliver voting datasets. Some of these projects involved voting records by members of parliament (MPs). Other projects were about voting records from general election where official websites display results on a website, but do not give as clean dataset. Such datasets are interesting for Big Data analysis in the political environment.
Yelp. Our goal was to get listings of all businesses providing Accounting services in certain US cities. We built a quick and effective robot on our Steps framework to do the job. Our Yelp robot can be resued to scrape Yelp datasets on any type of business in any geographic area.
- Social Networks. In 2014 we started an experimental project to gather and mesh together public footprints that users leave on most prominent social networks like Facebook and Linkedin with some smaller niche and interest specific social networks (think Stackoverflow, etc). The results should be an interesting dataset.
- Endomondo Vizualization Maps. We wanted to study where inhabitants of Vilnius go running, riding bikes (especially mountain bikes). Why do it? Answer is simple: looking at such crowdsourced map gives us a lot of ideas of new trails to explore. We leveraged Endomondo Challenges popular among Lithuanians to access GPS data of thousands of tracks. From the technical perspective crawling Endomondo was a really good showcase of our robots because Endomondo uses a lot AJAX to load data dynamically. The results were very nice, so we published data for the community.

Online Retail Datasets. Our client needs data feed (Brand, Name, Description, Ingredients, Price, SKU, Picture, etc) about beauty products sold at multiple major online shops. We setup scraper robots that go through the targeted product categories and collect data about all products along with intelligent pre-processing like identifying ingredient lists and application instructions in the description text. Data from all sources is normalised into single schema and delivered to client in CSV format.
