
Instant Data Scraper Update
In October and November of this year we decided to survey Instant Data Scraper extension users to see where Web Robots team should focus for the next update. We already had some ideas from user emails that we received over last couple years, but we needed a more scientific proof to see which features would be most desired. Among features we consider things like infinite scroll support, running jobs on cloud, processing batches of URLs, proxy support, etc.
Before the end of the survey it became clear that infinite scroll support is by far most desired feature and decided to release it as soon as possible. One December 11th we published a 0.2.0 version to Chrome Webstore. Enjoy it!
Other features […]
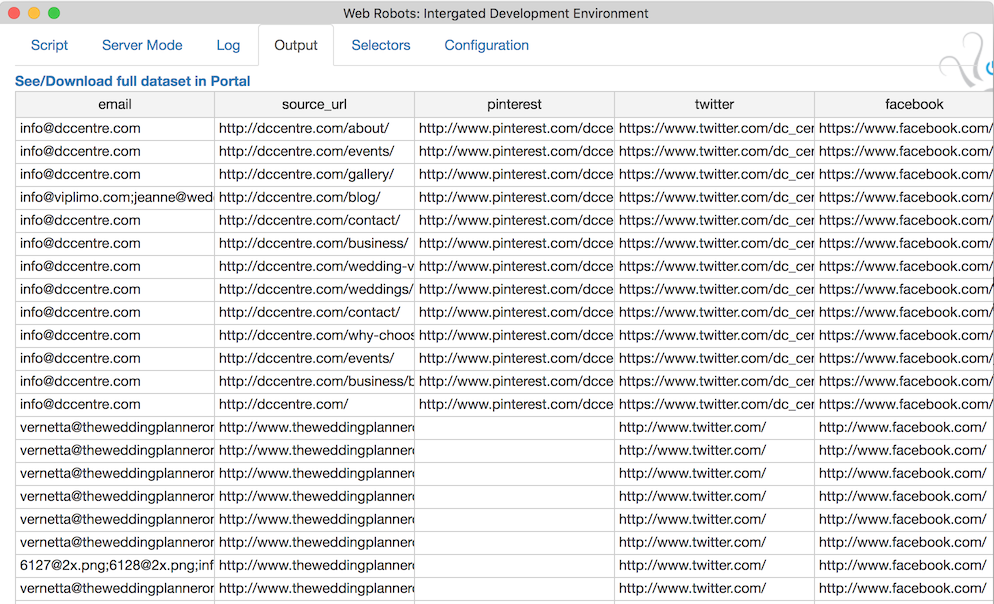
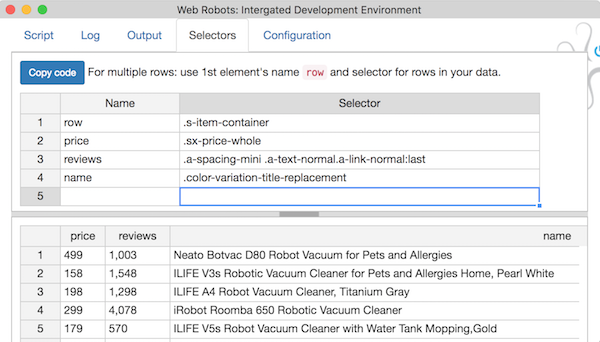

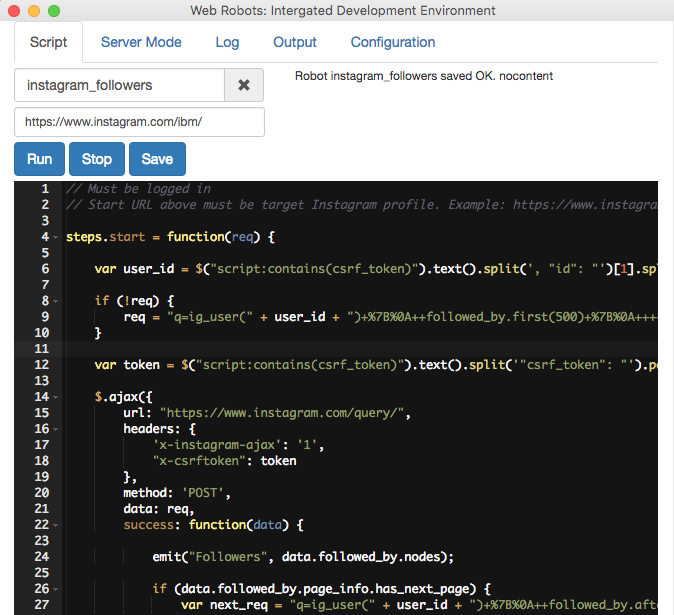
![Screen Shot 2016-03-01 at 3.22.41 [...]
</p srcset=](https://webrobots.io/wp-content/uploads/2016/03/Screen-Shot-2016-03-01-at-3.22.41-PM-1024x849.png)