New Features
We are happy to announce some new features in our robot writing framework. These features are:
- Fork() – split robot into many parallel robots and run them simultaneously. This feature shortens long scraping jobs by parallelising them. Cloud autoscaling handles necessary instance capacity so our customers can run 100s of instances on-demand.
- skipVisited – allows robot to intelligently skip steps to links that were already visited. Avoid data duplication, save robot running time.
- respectRobotsTxt – crawl target sources with compliance to their robots.txt file.
These features are explained in detail and examples added to our framework documentation page.
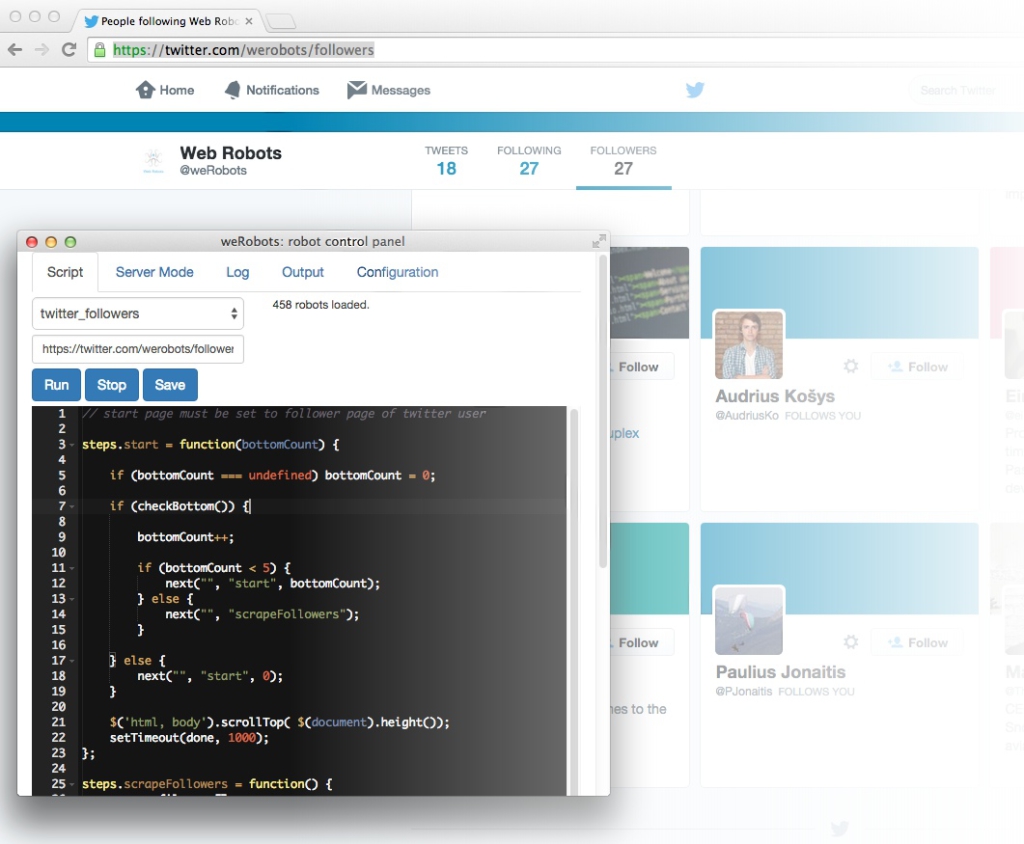 Easy Twitter Scraping
Easy Twitter Scraping